
Machine Learning is very much in vogue at the moment and there are many Android folks producing some excellent guides to creating and training models. However, I do not feel that in the vast majority of cases Android Developers will be required to train their own models. But that does not mean that using a model that someone else has created is a straightforward task. In this short series, we’ll take a look at some of the problems and pain points that I encountered while attempting to incorporate a pre-trained TensorFlow Lite model in to an Android app.

To start with I should really explain that bold assertion that I made in the introductory text: I do not feel that in the vast majority of cases Android Developers will be required to train their own models. My reasoning here is that creating and training an AI or ML model is a discipline somewhat different to Android development. In the vast majority of cases Android developers will not be required to do this because there will be specialised teams responsible for this. In the same way that many projects will have a team responsible for backend web services that will be consumed by Android, iOS, and web clients, companies developing AI / ML based solutions will have a separate team dedicated to creating and refining the model which can then be used across multiple clients.
That would appear to make the app developers’ jobs a lot easier, and that is very much the case. However there are still some pitfalls which exist in part because this is all very new and implementing a model that someone else has created, still requires some knowledge and understanding of that model in order to properly incorporate it in to an Android app.
Let’s start with a basic understanding of what we’re trying to achieve, and set the starting point. One of the standard models that is included with TensorFlow is the MNIST handwritten numeric digit classifier. The MNIST dataset is a collection of hand-drawn numerical digits which can be use to train a model to recognise hand-drawn digits, and this felt that it would be fairly easy to write an Android app which would allow the user to draw a numeric digit on the screen, and it could use a model trained with the MNIST dataset to identify the digit which was typed.
In order to incorporate this in to the app, I would need to create a TensorFlow model, and convert this to TensorFlow Lite format (as we do not have a full TensorFlow runtime on Android, only TensorFlow Lite), and then incorporate this in to the app using MLKit. It was a conscious decision which I made at the beginning that I wanted to use MLKit rather than directly using TensorFlow Lite. The reasons for this should become apparent as we go.
So the first thing was to train up a model which I could incorporate. I won’t go in to detail here because that isn’t the point of this series of articles, but I will explain a little about the route I had to take. Firstly I tried using the official TensorFlow MNIST model. This was easy enough to train, but converting it to TensorFlow Lite proved tricky and I gave up. Next I found this project by Tianxing Li which uses the same MNIST dataset but contains scripts to train, and test the TensorFlow model, and then another script to convert it to TensorFlow Lite. There are full instructions on the project website for how to do that.
Some people might have noticed that the project that I used to generate the model also includes an Android app to do exactly the same as I was setting out to do. However, there is one important distinction: It incorporates the model using the Android TensorFlow Lite library directly, whereas I wanted to use MLKit. While this may not seem like a big change, I encountered quite a few problems and misunderstandings along the way, which I’ll be sharing as we go, so it felt like a worthwhile exercise to be able to document these.
So with our model trained and converted to TensorFlow Lite, we’re ready to start building the app, right? Well, not quite. Although in reality, that’s precisely what I did, I encountered some problems quite early on which caused quite a bit of head scratching and frustration. Although I had my model, I had no idea of the input and output formats that of the data. I knew that the MNIST dataset consisted of a number of image files, each one was 28×28 pixels, and I was able to infer certain things by studying Tianxing’s Android code. However, this will not be the case if you are simply given the model. The best option here would be to speak with the team that created the model to obtain the input and output formats, but I also found a useful tool which can obtain them directly from the model itself. The tool is part of the TensorFlow Github repo and creates an HTML visualisation of a TensorFlow Lite model.
To run it you must first install Bazel to build the tool. Instructions for installing Bazel are available for a number of operating systems here. Once Bazel is installed, you need to clone the TensorFlow repo:
git clone https://github.com/tensorflow/tensorflow.gitNext we need to build the visualizer tool:
$ cd tensorflow
$ bazel build tensorflow/contrib/lite/tools/visualize Once this has built successfully (it may take quite a while – it took about 30 minutes on my 4 GHz Intel Core i7 iMac) it can be used to generate a visualisation of the TensorFlow Lite model:
bazel-bin/tensorflow/contrib/lite/tools/visualize model.tflite model.htmlThe generated html file can be opened in a browser to see the visualisation of the model. It’s nothing very pretty but gives us some useful information:
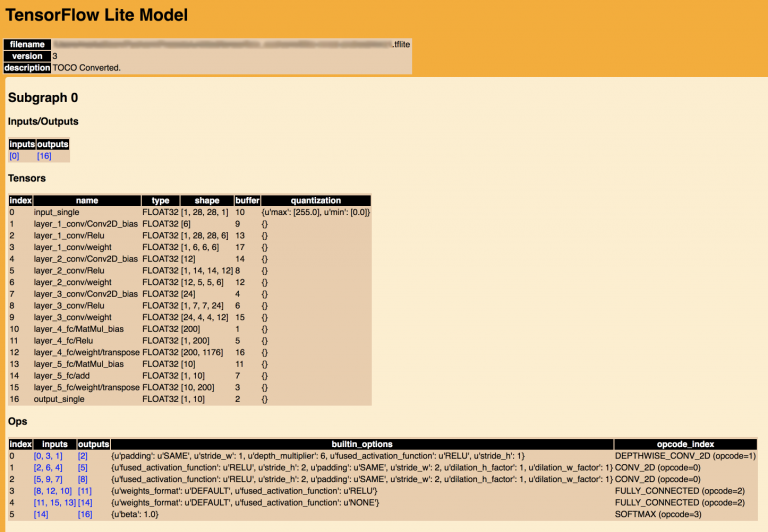
The bit we’re interested in here is the Inputs/Outputs section which indicates that the tensor at index 0 is the input, and the one at index 16 is the output.
The input has a shape of [1, 28, 28, 1] which is a vector which describes the input data. The first number is the batch size, so this is a fixed size of 1 meaning that we’ll only pass in a single image for analysis. The second and third digits represent the width and height of the image we want to analyse. The training data was a set of 28×28 images, so we need to provide a 28×28 pixel image for analysis. The fourth digit is the number of values for each pixel. In this case each pixel will be represented by a FLOAT32 (from the type field). This will represent a greyscale value from 0.0 (black) to 1.0 (white), which is how the data is represented in the images used to generate the model. It is important that the representation of the image that we want to analyse matches the representation of the training images.
The output has a shape of [1, 10] which is a vector which describes the output data. The first number is, once again, the batch size. If we supplied multiple images in the input, then this value would tally with the value from the input. The second digit represents the classifications. In this case the model will identify the digits from 0-9 inclusive, and each of these classifications will have a FLOAT32 (as seen in the type field) value indicating the probability that the analysed image. So the identified value will be the index of the highest probability:
[7.906156E-16, 2.7768906E-15, 3.609502E-14, 1.0,
5.1401704E-20, 2.7919297E-12, 7.474837E-17, 6.025316E-17,
1.3942689E-16, 3.370442E-19]In this case the most of the numbers are pretty small with the exception of the fourth element. As the index is a zero-based that means that the digit has been pretty clearly identified as the number ‘3’.
So we have our trained TensorFlow Lite model, and we have identified and understood the inputs and outputs of the model. Now we are actually ready to start implementing this in to our app, and we’ll start looking at that in the next article in this series.
There’s no actual code to show at this point, but the code will be published along with the article which covers it.
© 2018, Mark Allison. All rights reserved.
Copyright © 2018 Styling Android. All Rights Reserved.
Information about how to reuse or republish this work may be available at http://blog.stylingandroid.com/license-information.

Nice info about TensorFlow !!!!
AI/ML makes Android developers life easy.lots of new features are about to come in Android development