
Although the number of typos which appear in my blog posts may suggest otherwise, I am quite keen on good grammar. One specific area of this, which is nice to get right, is the display of ordinal numbers in their abbreviated form. In plain English, this means that when we shorten the word ‘first’ to 1st, we display the ‘st’ as superscript: i.e. we show 1st and not 1st. It is particularly nice to do this when displaying dates in the form ‘1st January’. In this article we’ll cover a technique for doing precisely that.
 Before we begin, it is worth pointing out that even though the example code that we’ll use will cover this English language case, the potential applications for this are not limited just to English, we could easily adapt it to work with other languages such as Italian where we would handle 1o.
Before we begin, it is worth pointing out that even though the example code that we’ll use will cover this English language case, the potential applications for this are not limited just to English, we could easily adapt it to work with other languages such as Italian where we would handle 1o.
Regular readers of Styling Android will know that I am rather partial to Spans and it will probably come as no surprise that they are a key part of the technique that we’re going to use. The other key component is a regular expression to match ordinals in any given source string. The real power of this technique comes with the regular expression that we use, so let’s begin by taking a look at it:
(?<=\b\d{1,10})(st|nd|rd|th)(?=\b)
Although that may look a little scary, let's examine it piece by piece. There are three sections to this which are denoted by the top level parentheses, which specify three character groups:
(?<=\b\d{1,10})
(st|nd|rd|th)
(?=\b)
The first section is a lookbehind. A lookbehind will match specific patterns which occur before the section that we wish to capture without including them within the capture group. A lookbehind is specified using ?<= and the section that follows it is the pattern that we wish to match. In this case \b\d{1,10} will match either a whitespace character or the start of the string (that's what the \b does); followed by between 1 and ten digits (that's what the \d{1,10} does. It is not possible to use wildcard matches in lookbehinds in Java - the regex compilation will fail if the compiler cannot determine the maximum length of the lookbehind, that why I specify a range here, rather than just using \\d+
The middle section specifies what we actually want to capture. As we want to correctly handle the correct ordinal suffixes 1st, 2nd, 3rd, and 4th, we include all of these: (st|nd|rd|th).
The final section is a lookahead. A lookahead will match specific patterns which occur after the section that we wish to capture without including them within the capture group. A lookahead is specified using ?= and the section that follows that is the pattern we wish to match. In this case \b will match either a whitespace character or the end of the string.
This may seem like over engineering, why can't we just use the middle section on its own? To understand this but we need to consider cases like the word 'first'. If we were to just use the middle component of our regex in isolation, it would match on the 'st' in 'first' and we would get first which is not what we want.
The lookbehind and lookahead enable us to specify a context where we want to match those characters. so the pattern that we'll match is:
<whitespace or start><one or more digits>st|nd|rd|th<whitespace or end>
But the only part that will actually be captured by the regex is the st, nd, rd, or th as this is the part of the string we actually need to make superscript. In the example code there is a JUnit 5 test suite. This is mainly testing the behaviour of the regex and ensuring that it matches where it should and doesn't match where it shouldn't. Check out the test cases for some more examples of strings which could result in incorrect matches.
My regex isn't perfect. I'm fully aware that there are some corner-cases which could cause issue. For example this would positively match 11st even though this is grammatically incorrect. Although I could make the regex more specific to follow the correct grammatical rules, I feel this would add unnecessary complexity to the regex and prefer the simpler form that I'm using here.
So we have a regex which will capture the groups of characters we wish to make superscript, what remains is to apply the necessary formatting. This is done by applying two span on each captured group. The first is a SuperscriptSpan which will raise the baseline of the text within the span, and the second is RelativeSizeSpan which will change the size of the span relative to the text size of the TextView. The code for doing all of this is:
public class OrdinalSuperscriptFormatter {
private static final String SUPERSCRIPT_REGEX = "(?<=\\b\\d{0,10})(st|nd|rd|th)(?=\\b)";
private static final Pattern PATTERN = Pattern.compile(SUPERSCRIPT_REGEX);
private static final float PROPORTION = 0.5f;
private final SpannableStringBuilder stringBuilder;
public OrdinalSuperscriptFormatter(@NonNull SpannableStringBuilder stringBuilder) {
this.stringBuilder = stringBuilder;
}
public void format(TextView textView) {
CharSequence text = textView.getText();
Matcher matcher = PATTERN.matcher(text);
stringBuilder.clear();
stringBuilder.append(text);
while (matcher.find()) {
int start = matcher.start();
int end = matcher.end();
createSuperscriptSpan(start, end);
}
textView.setText(stringBuilder);
}
private void createSuperscriptSpan(int start, int end) {
SuperscriptSpan superscript = new SuperscriptSpan();
RelativeSizeSpan size = new RelativeSizeSpan(PROPORTION);
stringBuilder.setSpan(superscript, start, end, Spanned.SPAN_EXCLUSIVE_EXCLUSIVE);
stringBuilder.setSpan(size, start, end, Spanned.SPAN_EXCLUSIVE_EXCLUSIVE);
}
}
The regex pattern matching logic is executed within the format() method, and the spans are applied in the createSuperscriptSpan() method.
To apply this is pretty simple:
public class MainActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
TextView textView = (TextView) findViewById(R.id.text_view);
OrdinalSuperscriptFormatter formatter = new OrdinalSuperscriptFormatter(new SpannableStringBuilder());
formatter.format(textView);
}
}
Running this produces the following:
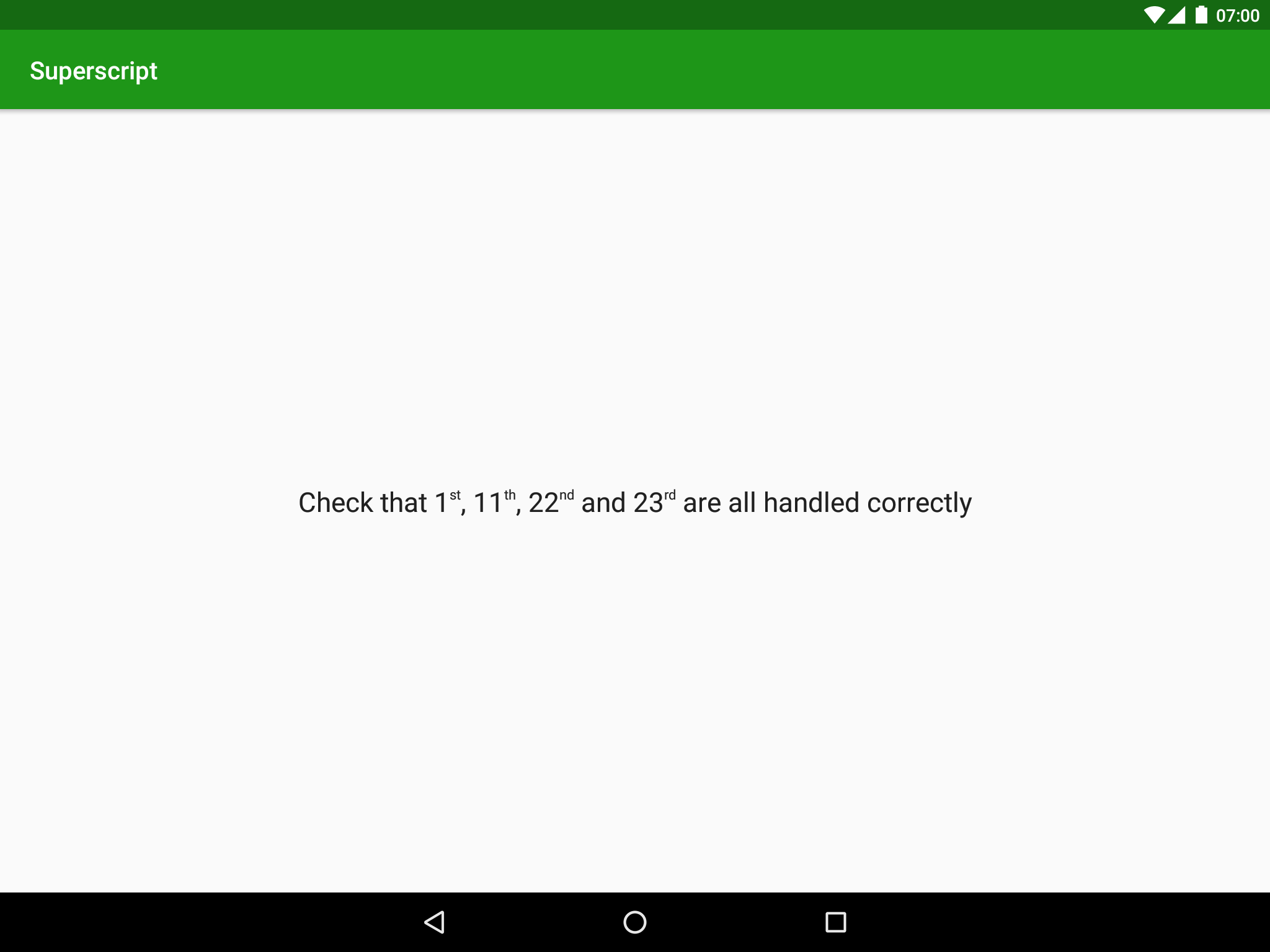
Of course the same concept of using a regex to match specific pattern within a string and applying spans to the areas which match is pretty powerful and can be used in many other ways.
The source code for this article is available here.
© 2017, Mark Allison. All rights reserved.
Copyright © 2017 Styling Android. All Rights Reserved.
Information about how to reuse or republish this work may be available at http://blog.stylingandroid.com/license-information.

Hi
I hope you are doing well
I used your code for making superscripts with numbers, but Unfortunately, I am unable to get those superscripts with a number.
I am passing “1”, “2” as text and matcher.find() returning false every time, I don’t know what is going on either with the pattern or with my text.
Please help me out.